The Scalar Kalman Filter
This document gives a brief introduction to the derivation of a Kalman
filter when the input is a scalar quantity. It is split into several sections:
Defining the Problem
Discrete time linear systems are often represented in a state
variable format given by the equation:
 Equation 1
Equation 1
where, for this discussion, the state, xj, is a scalar, a and b are
constants and the input uj is a scalar; j represents the time variable.
Note that many texts don't include the input term (it may be set to zero), and
most texts use the variable k to represent time. I have chosen to
use j to represent the time variable because we use the variable k for
the Kalman filter gain later in the text. The equation states that the current value of the variable (xj) is equal to the last value (xj-1) multiplied by a constant (a) plus the current input (uj) mulitiplied by another constant (b). Equation 1 can be represented
pictorially as shown below, where the block with T in it represents a time
delay (the input is xj, the output is xj-1). Note: some books will use z-1 or 1/z in place of T.

Figure
1
Now imagine some noise is added to the process such that:
 Equation 2
Equation 2
The noise, w, is white noise source with zero mean and
covariance Q and is uncorrelated with the input. The process can now be represented as shown:
 Figure
2
Figure
2
Given a situation like the one shown above, a typical question might be: Can
we filter the signal x so that the effects of the noise w
are minimized? The answer, it turns out is yes. However, with Kalman
filters we can go one step further.
Let us assume that the signal x is not directly measured, but instead
we measure z which is x multiplied by a gain (h) with noise added (v).
 Equation 3
Equation 3
The measured value z depends on the current value of x,
as determined by the gain h. Additionally, the measurement has
its own noise, v, associated with it. The noise, v, is white noise source with zero mean and
covariance R and is uncorrelated with the input or with the noise w. The two noise sources are independent of each other and
independent of the input.
 Figure
3
Figure
3
The task of the Kalman filter can now be stated as: Given a
system such as the one shown above, how can we filter z so as to estimate
the variable x while minimizing the effects of w and v?
It seems reasonable to achieve an estimate of the state (and the
output) by simply reproducing the system architecture. This simple (and ultimately useless) way to get an estimate of xj (which we will callx^j),
is diagrammed below.
 Figure
4
Figure
4
This approach has two glaring weakness. The first is that
there is no correction. If we don't know the quantities a, b or h exactly (or the initial value x0), the estimate will not track
the exact value of x. Secondly, we don't compensate for the addition of
the noise sources (w and v). An improved arrangement which
takes care of both of these problems is shown below.
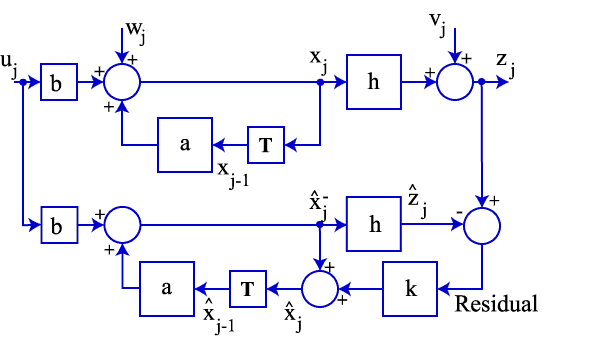 Figure
5
Figure
5
This figure is much like the previous one. The first
difference noted is that the original estimate of xj is now called x^j-;
we will refer to this as the a priori estimate.
 Equation 4
Equation 4
We use this a priori estimate to predict an estimate for the output, z^j. The difference between
this
estimated output and the actual output is called the residual, or innovation.
 Equation 5
Equation 5
If the residual is small, it generally means we have a good
estimate; if it is large the estimate is not so good. We can use this
information to refine our estimate of xj; we call this new estimate
the a
posteriori estimate, x^j.
If the residual is small, so is the correction to the estimate. As
the residual grows, so does the correction. The pertinent equation is (from the block diagram):
 Equation 6
Equation 6
The only task now is to find the quantity k that is used to
refine our estimate, and it is this process that is at the heart of Kalman
filtering.
Note: We are trying to find an optimal estimator, and
thus far we are only optimizing the value for the gain, k. We have
assumed that a copy of the original system (i.e., the gains a, b, and h
arranged as shown) should be used to form the estimator. This begs the
question: "Is the estimator as developed above
optimal?" In other words, should we simply copy the
original system in order to estimate the state, or is there perhaps a better
way? The answer it turn out, is that the estimator, as shown above, is
the optimal linear estimator that can be developed. The details
are here.
Finding K, the Kalman Filter Gain
(you can skip the next three sections if you
are not interested in the math).
To begin, let us define the errors of our estimate. There
will be two errors, an a priori error, ej-,
and an a posteriori error, ej. Each one is defined as the
difference between the actual value of xj and the estimate (either a
priori or a posteriori).
 Equation 7
Equation 7
Associated with each of these errors is a mean squared error, or
variance:
 Equation 8
Equation 8
where the operator E{ } represents the expected, or
average, value. These definitions will be used in the calculation of the quantity k.
A Kalman filter minimizes the a posteriori variance, pj,
by suitably choosing the value of k. We start by substituting equation 6 into equation 8.
 Equation 9
Equation 9
To find the value of k that minimizes the variance we
differentiate this expression with respect to k and set the derivative to zero.
Be patient here, the expression gets much messier before it becomes simple.
 Equation 10
Equation 10
We take this last expression and use it to solve for k.
 Equation 11
Equation 11
This expression is still quite complicated. To simplify it
we will consider the numerator and the denominator separately.
We start with the numerator, and substitute in equation 3 for zj.
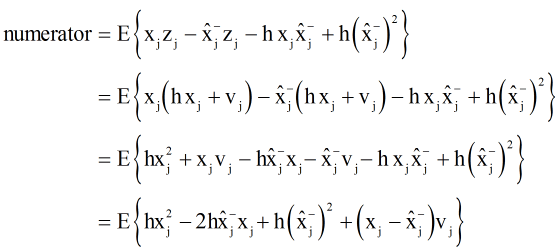
The measurement noise, v, is uncorrelated to either the input or
the a priori estimate of x, so:
 Equation 12
Equation 12
This simplifies the expression for the numerator.
 Equation 13
Equation 13
Now, in the same way, consider the denominator.
 Equation 14
Equation 14
Again, we can use the orthogonality condition from equation 12 to set the last term to
zero, so:
 Equation 15
Equation 15
where we used the simplification from equation 13 for the first
term in the expression, and using the definition of the measurement noise for
the second term.
Using the expression for numerator and denominator, we finally
get a simple expression for k:
 Equation 16
Equation 16
However, there is still a problem because this expression needs
a value for the a priori covariance which in turn requires a knowledge of the
system variable xj. Therefore our next task will be to find an estimate for the a priori covariance.
Before we move on, let's look at this equation in detail.
First note that the "constant", k, changes at every iteration.
For this reason it should really be written with a subscript (i.e., kj).
We'll be more careful about this later.
Next, and more significantly, we can examine what happens
as each of the three terms in equation 16 are varied.
- If the a priori error is very small, k is correspondingly
very small, so our correction is also very small. In other words we
will ignore the current measurement and simply use past estimates to form
the new estimate. This is as expected -- if our first estimate (the
a priori estimate) is good (i.e., with small error) there is very little
need to correct it.
- If the a priori error is very large (so that the measurement
noise term, R, in the denominator is unimportant) then k=1/h. This, in
effect, tells us to throw away the a priori estimate and use the current
(measured) value of the output to estimate the state. This is made clear by
substitution into equation 6. Again, this is as expected -- if the a
priori error is large then we should disregard the a priori estimate, and
instead use the current measurement of the output to form our estimate of
the state.

- If the measurement noise, R, is very large, k is again
very small, so we disregard the current measurement in forming the new
estimate. This is as expected -- if the measurement noise is
large, then we have low confidence in the measurement and our estimate will
depend more upon the previous estimates.
Finding the a priori covariance
Finding the a priori covariance is straightforward starting with
its definition.

The middle term drops out as before because the process noise is
uncorrelated with previous values of the either the state or its a priori
estimate.
 Equation 17
Equation 17
so
 Equation 18
Equation 18
We are still not finished, however, because we need an
expression for pj, the a posteriori variance.
Finding the a posteriori covariance
As with the a priori covariance, we find the a posteriori
covariance by starting with its definition.
 Equation 19
Equation 19
The middle term drops out as before because the measurement noise is
uncorrelated with the current values of the either the state or its a priori
estimate.
 Equation 20
Equation 20
So
 Equation 21
Equation 21
We can simplify this by using our previous definition for k (Equation 16 rearranged)
 Equation 22
Equation 22
Substituting Equation 22 into Equation 21 yields
 Equation 23
Equation 23
Review of Pertinent Results
(Some of this is repeated from above)
Any Kalman filter operation begins with a system description
consisting of gains a, b and h. The state is x,
the input to the system is u, and the output is z. The time
index is given by j.

The process has two steps, a predictor step (which calculates
the next estimate of the state based only on past measurements of the output),
and a corrector step (which uses the current value of the estimate to refine the
result given by the predictor step).
Predictor Step
We form the a priori state estimate based on the previous
estimate of the state and the current value of the input.
We can now calculate the a priori covariance

Note that these two equations use previous values of the a
posteriori state estimate and covariance. Therefore the first
iteration of a Kalman filter requires estimates (which are often just
guesses) of the these two variables. The exact estimate is often not
important as the values converge towards the correct value over time; a
bad initial estimate just takes more iterations to converge.
Corrector Step
To correct the a priori estimate, we need the Kalman
filter gain, k.

This gain is used to refine (correct) the a priori
estimate to give us the a posteriori estimates.

We can now calculate the a posteriori covariance

Notes about the Kalman filter gain,
kj.
-
If the a priori error is very small, k is correspondingly
very small, so our correction is also very small. In other words we
will ignore the current measurement and simply use past estimates to form
the new estimate. This is as expected -- if our first estimate (the
a priori estimate) is good (i.e., with small error) there is very little
need to correct it.
-
If the a priori error is very large (so that the measurement
noise term, R, in the denominator is unimportant) then k=1/h. This, in
effect, tells us to throw away the a priori estimate and use the current
(measured) value of the output to estimate the state. This is made clear by
substitution into equation 6. Again, this is as expected -- if the a
priori error is large then we should disregard the a priori estimate, and
instead use the current measurement of the output to form our estimate of
the state.
-
If the measurement noise, R, is very large, k is again
very small, so we disregard the current measurement in forming the new
estimate. This is as expected -- if the measurement noise is
large, then we have low confidence in the measurement and our estimate will
depend more upon the previous estimates.
Alternate, More Common, Notation
The notation used in this document was taken from [1].
More common notation is given below.
| Variable |
Notation in this
Document |
More Common
Notation |
| time variable |
j |
k |
| state |
xj |
x(k) |
| system gains |
a, b, h |
a, b, h (note: b is often 0) |
| input |
uj |
u(k) (note:
often there is no input) |
| output |
zj |
z(k) |
| gain |
kj |
Kk |
| a priori estimate |
 |
 |
| a posteriori estimate |
 |
 |
| a priori covariance |
pj- |
p(k|k-1) or p(k+1|k) |
| a posteriori covariance |
pj |
p(k|k) or p(k+1|k+1) |
The notation

can be read as "The estimate of x at time k, based on the
information from time k-1"; in other words, the estimate based only upon the past
values of the output, or the a priori estimate. The notation

can be read as "The estimate of x at time k, based on the
information from time k"; in other words the estimate based on past and current values of the output, or the a posteriori estimate
Examples
-
Example of estimating a constant (along with Matlab code).
-
Example of estimating a first order process (along with Matlab code).
Going further
A matrix based (higher order system) Kalman filter is a simple
extension of the scalar case presented here. The results are given here,
a full description of the mathematics can be found in the reference [3].
References
[1] An Introduction to Kalman Filters,
G Welch and G Bishop, http://www.cs.unc.edu/~welch/kalman/kalman_filter/kalman.html.
See also their other introductory
information on Kalman Filters.
[2] Handbook of Digital Signal Processing, D Elliot ed,
Academic Press, 1986.
[3] Digital and Kalman filtering : an introduction to
discrete-time filtering and optimum linear estimation, SM Bozic,
Halsted Press, 1994.
[4] An Engineering Approach to Optimal Control and Estimation
Theory, GM Siouris, John Wiley & Sons, 1996.
[5] Statistical and Adaptive Signal Processing, DG
Manolakis, VK Ingle, SM Kogon, McGraw Hill, 2000.
[6] Smoothing, Filtering and Prediction - Estimating The
Past, GA Einicke, a free on-line text:http://www.intechopen.com/books/smoothing-filtering-and-prediction-estimating-the-past-present-and-future
[7] Understanding the Basis of the Kalman Filter Via a
Simple and Intuitive Derivation, R Faragher, IEEE SIG PROC MAG, [128]
Sept. 2012 http://www.cl.cam.ac.uk/~rmf25/papers/Understanding%20the%20Basis%20of%20the%20Kalman%20Filter.pdf
This article has a good intuitive description based on noise distributions.